Our Process
From data aquisition to f1 scores, and everything in between.
-

Choosing Data:
UCI Machine Learning Repository
Wine quality is a classic dataset for machine learning analysis, and we were able to source three main datasets to start playing with. UCI had a wine quality datasets, one for red and one for white. It featured measurements of different chemicals and elements of wines, and their associated quality rating. We thought it would be interesting to see if a model could predict if the wine was white or red based on some chemical features such as residual sugar and acidity.
-

Choosing Data
Kaggle Wine Reviews of the World
Another robust dataset we found was through kaggle.com and featured over 130,000 rows of data with wine maker, region, price, and score from wine magazine critics. We were interested to see if using Natural Language Processing on the descriptions given by the wine critics if the model could predict relative wine score or price.
-
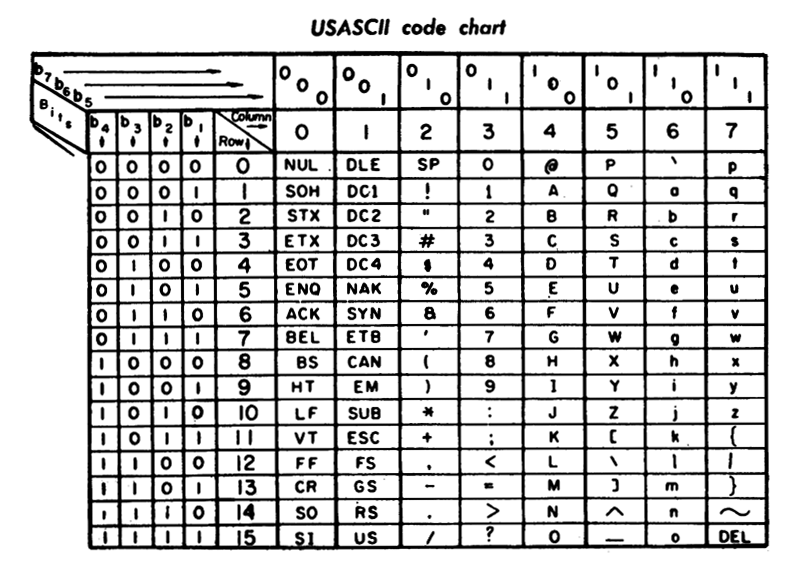
Data Cleaning and Initial Exploration
Some of the wine reviews had missing values, and non ascii-characters which we removed. The vintage of each wine was also situated inside the wine description rather than its own column. Some of the vintages didnt seem to make sense (1934?) and some of the prices looked to be mismarked. Overall we had to remove about 3,000 rows of data and manually clean several.
-
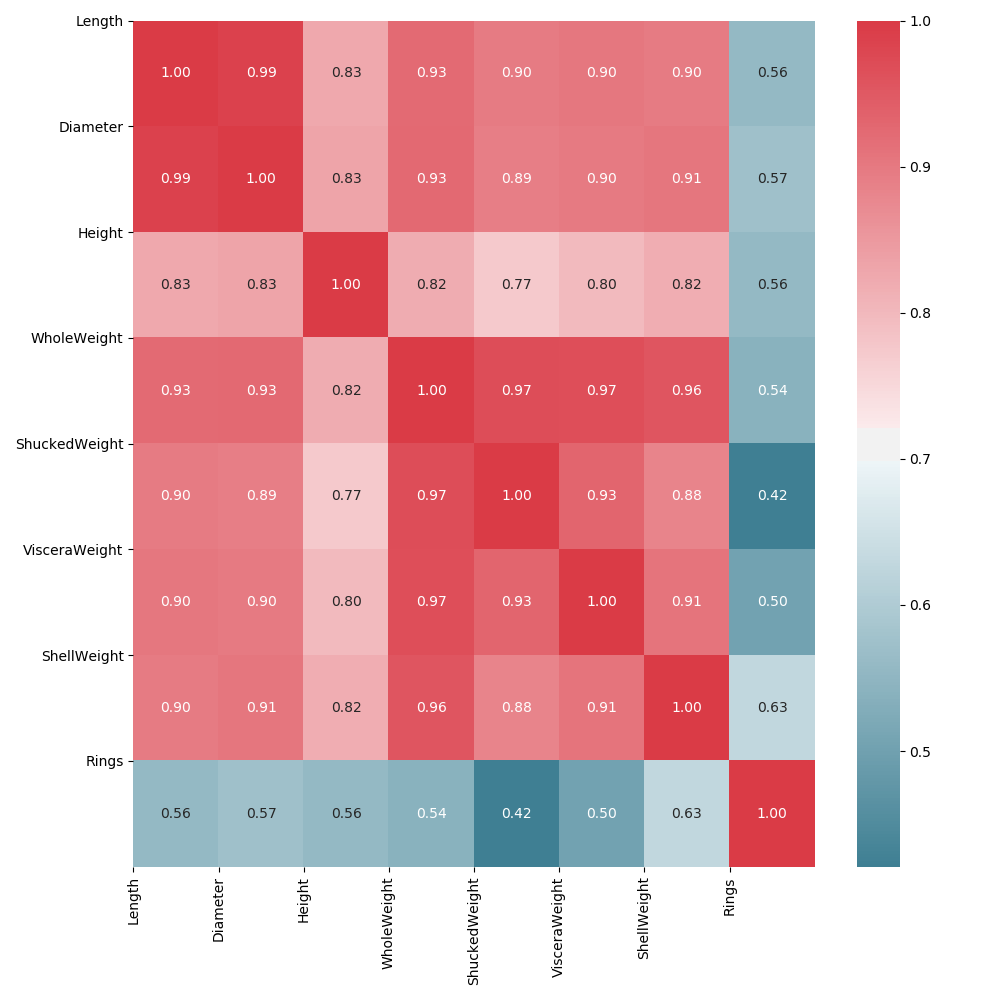
Initial Analysis
Using pyspark heatmaps and confusion matrices, we looked at relationships in wine quality and chemical makeups of red and white wines. We played with different combinations of features to see which models were accurate, innacurate, or seemingly overfitted.
-

Natural Language Processing
Wine Reviews
Using Google Colab and an NLP pipeline we attempted to use a model to predict ranges of scores and prices for the wine based on the content of the critic's review
-
Salud!



