Predicting Rating by Length of Review
Can the length of a review be relative to the final score a wine receives? We decided to take a deep look into this question and determine how likely it is that the length of the review has any consistency in relation to the score. This example of natural language processing was heavily inspired by the Yelp reviews activity which were comparing only positive and negative reviews where here we have a larger range of options as opposed to a binary result.
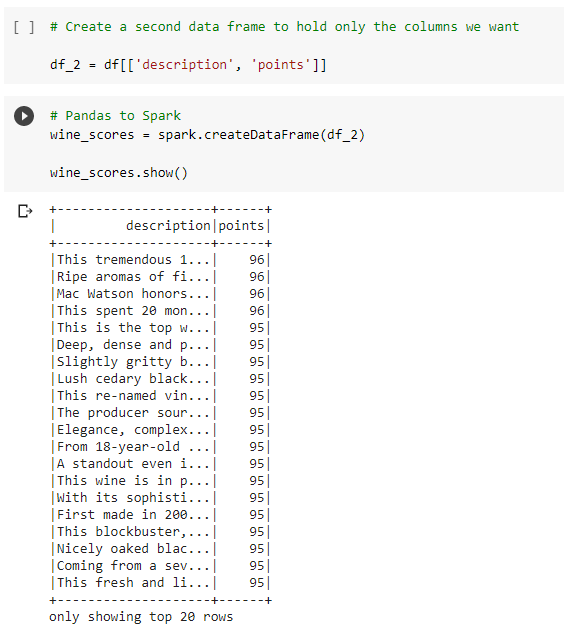
Originally the data was imported using pyspark but this caused issues when using the points column later on in the project. The description column would be placed in the labels column with the points causing more features than wanted. With Kelly’s help we were able to resolve this issue by first putting that data into a Pandas dataframe and cleaning it to only hold the columns that were needed.

We were able to covert the pandas dataframe into a pyspark dataframe so that we could use regexp_place and run further processing. Regexp_replace removes any non-alphanumeric characters to further clean the data. Wine is international and has many words that use characters from languages that made it difficult to process in the format we had it in to begin with.
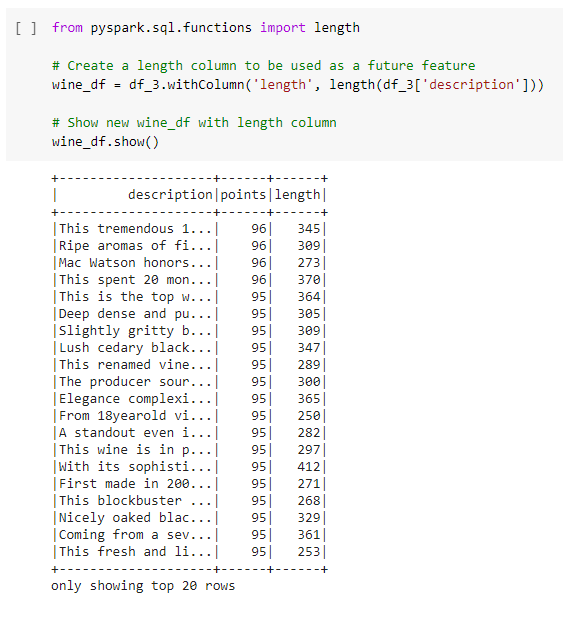
Here we created the length column to hold the number of words in each review.
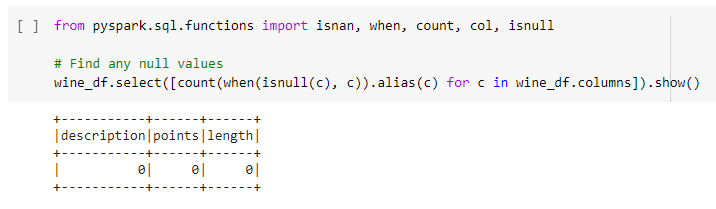
When further trying to learn the data we were having issues with any null spaces which led to more cleaning in the data. Before creating the pyspark dataframe we dropped an nulls in the Panda dataframe for easy conversion. Here we imported isnull for pyspark to check the columns and confirm it was clean and ready to teach.
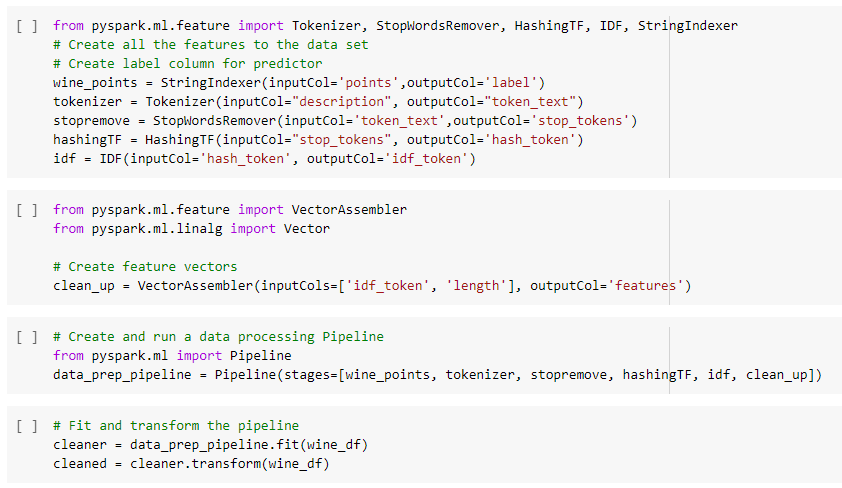
Now that the data is clean without any special characters or nulls we are ready to create the pipeline.
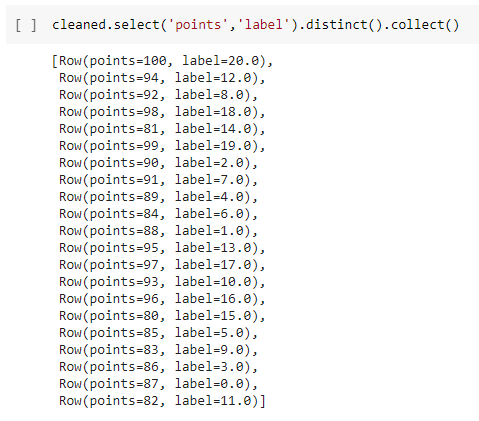
There are twenty one unique scores in the dataset with the most common being 88 points which was converted into a 0 label to represent the frequency, with 100 (the highest score) being assigned a 20 label.
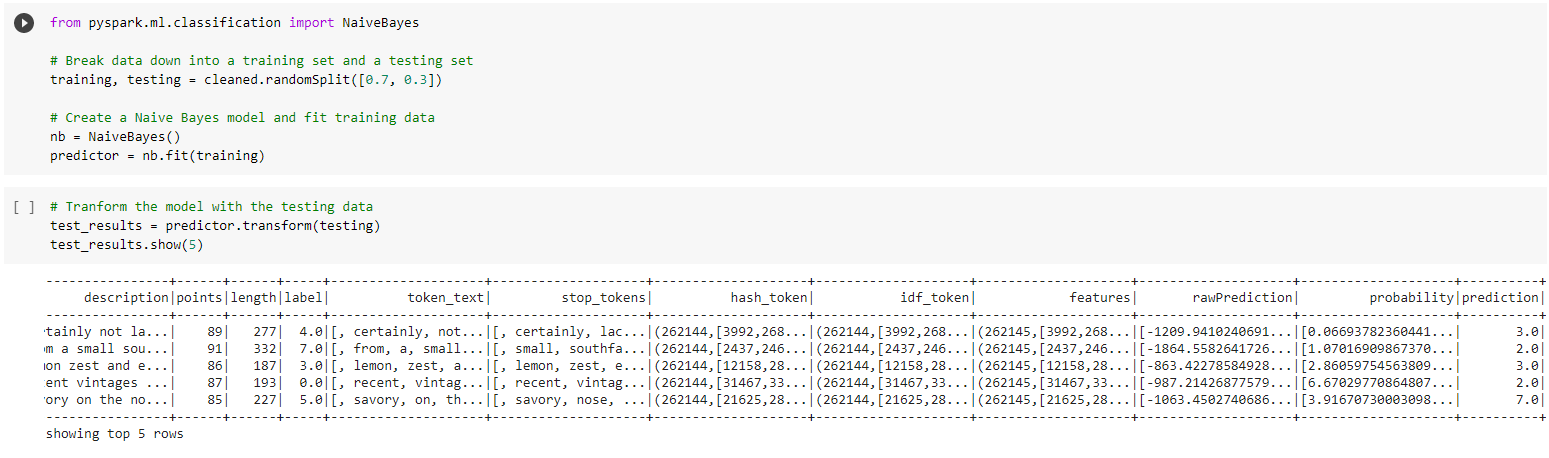
Next, we ran Naive Bayes and fit the training data then transformed the testing data.
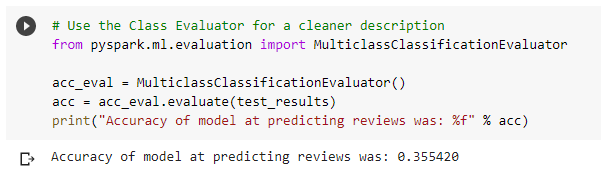
Ultimately this NLP project ended with 36% accuracy rating.
Predicting Wine Pricing by Length of Review
Could the length of a wine review be indicative of the price point of a particular wine? Following a similiar formula as with the wine score NLP, we set out to answer whether or not machine learning could be used to predict the price of a wine based on its description.
The same dataset, as used for the points model was imported into Pandas for the intial cleaning. The difference was all but the description column and the price column were dropped from the data frame.
Then all duplicates and null values were dropped from the data frame.
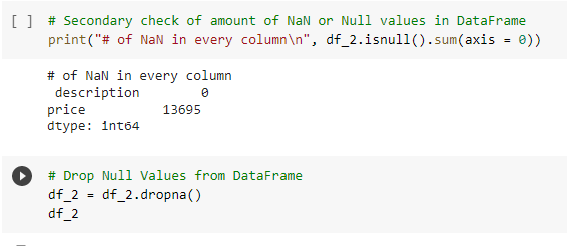
For the NLP model Pipeline to function, a description length column was created which is an integer output representative of the word length of the description.
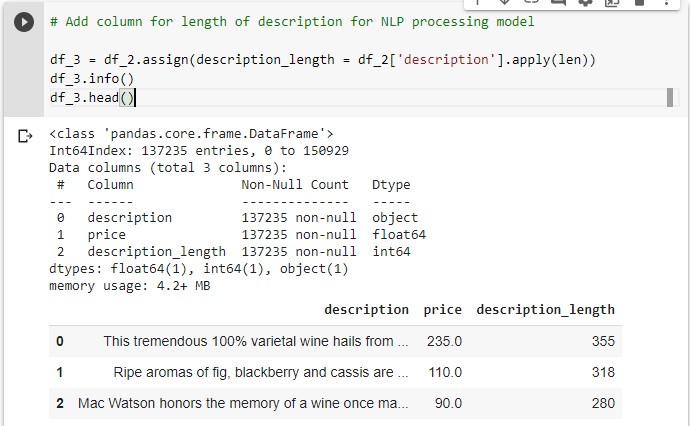
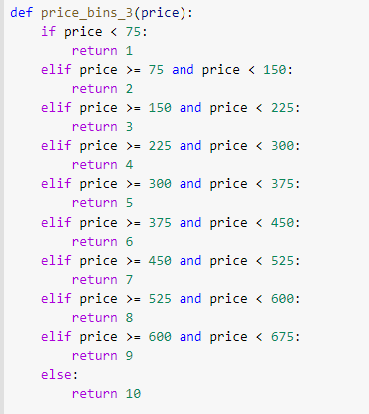
Differing from the wine points model above, the final piece of data cleaning was to create bins for the price points. In all five separate binning functions were created which would be commented on and off each time the code is run in order to show differnt ranges of wine prices to feed the model.
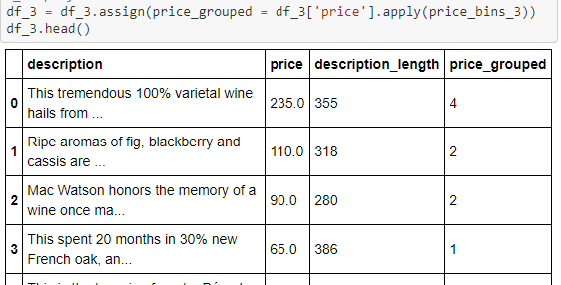
The binning function also outputted a new column called 'price_grouped' which was representative of each data point's respective bin based on their price range.
In order to gain insight into the distribution of the data, the bins were visualized through histograms which would be outputted after each individual binning function was ran.
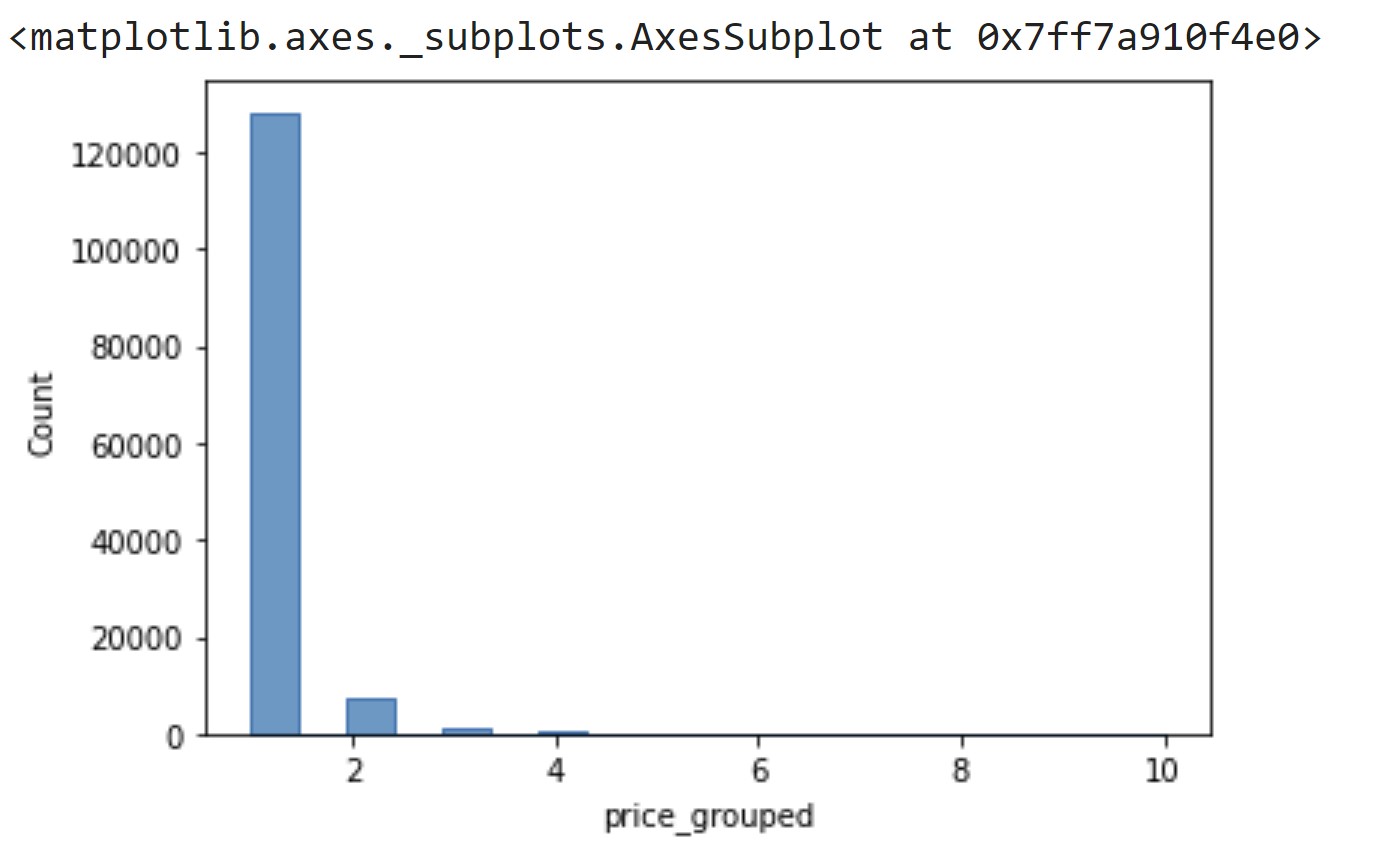
The histograms all tell a similar story, that the price data is skewed heavily to the left, which can be seen as the mean of the ‘price_grouped’ column for all binning function is less than 2.
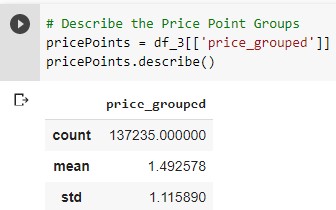
Now that the data was cleaned, the Pandas data frame is converted to a PySpark data frame and follows the exact same steps as above with the exception that the binned price column is used as the input column for the String indexer.

The following steps are identical to the wine score model with the NaiveBayes and MulticlassClassificationEvaluator libraries being utilized out ultimately output a prediction of accuracy. For four out of the five binning models utilized, the accuracy prediction was over 70%.
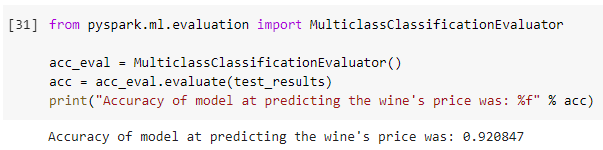
As a final note, to improve this project going forward incorporating cross validation into the model would be necessary. The current cross validation model from NaiveBayes, when ran in Google Collab required more RAM than offered by the program which caused the Multi Class cross validator to fail.